赛优市场店员积累了丰富的神秘顾客经验,严谨,务实,公平,客观.真实的数据支持!

【新智元导读】近日东莞市场研究公司,来自 MIT (麻省理工学院)的盘考东谈主员发表了对于大模子材干增速的盘考,扫尾标明,LLM 的材干大要每 8 个月就会翻一倍,速率远超摩尔定律!硬件惟恐就要跟不上啦!
咱们东谈主类可能要养不起 AI 了!
近日,来自 MIT FutureTech 的盘考东谈主员发表了一项对于大模子材干增长速率的盘考,扫尾标明:LLM 的材干大要每 8 个月就会翻一倍,速率远超摩尔定律!

LLM 的材干进步大部分来自于算力,而摩尔定律代表着硬件算力的发展,
—— 也即是说,跟着时期的推移,终有一天咱们将无法骄傲 LLM 所需要的算力!
如若阿谁时候 AI 有了意志,不知谈会不会我方想办法找饭吃?
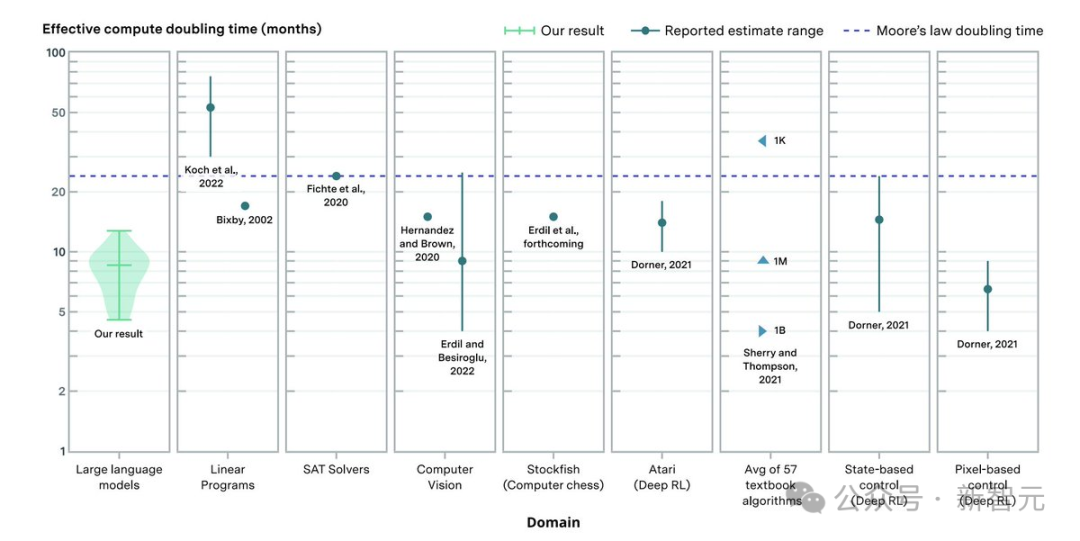
上图暗意不同界限的算法矫正对有用策画翻倍的忖度。蓝点暗意中心忖度值或范围;蓝色三角形对应于不同大小(范围从 1K 到 1B)的问题的倍增时期;紫色虚线对应于摩尔定律暗意的 2 年倍增时期。
摩尔定律和比尔盖茨
摩尔定律(Moore's law)是一种教授或者不雅察扫尾,暗意集成电路(IC)中的晶体管数目大要每两年翻一番。
1965 年,仙童半导体(Fairchild Semiconductor)和英特尔的长入首创东谈主 Gordon Moore 假定集成电路的组件数目每年翻一番,并预测这种增长率将至少再捏续十年。

1975 年,预计下一个十年,他将预测修改为每两年翻一番,复合年增长率(CAGR)为 41%。
诚然 Moore 莫得使用教授字据来预测历史趋势将不绝下去,但他的预测自 1975 年以来一直诞生,是以也就成了“定律”。
因为摩尔定律被半导体行业用于率领长久处案和设定研发方针,是以在某种程度上,成了一种自我终了预言。
数字电子技艺的跳跃,举例微经管器价钱的裁汰、内存容量(RAM 和闪存)的加多、传感器的矫正,以致数码相机中像素的数目和大小,齐与摩尔定律密切有关。
数字电子的这些捏续变化一直是技艺和社会变革、出产力和经济增长的驱能源。
不外光靠自我激发细则是不成的,诚然行业内行没法对摩尔定律能捏续多久达成共鸣,但根据微经管器架构师的陈述,自 2010 年傍边以来,通盘这个词行业的半导体发展速率依然放缓,略低于摩尔定律预测的速率。
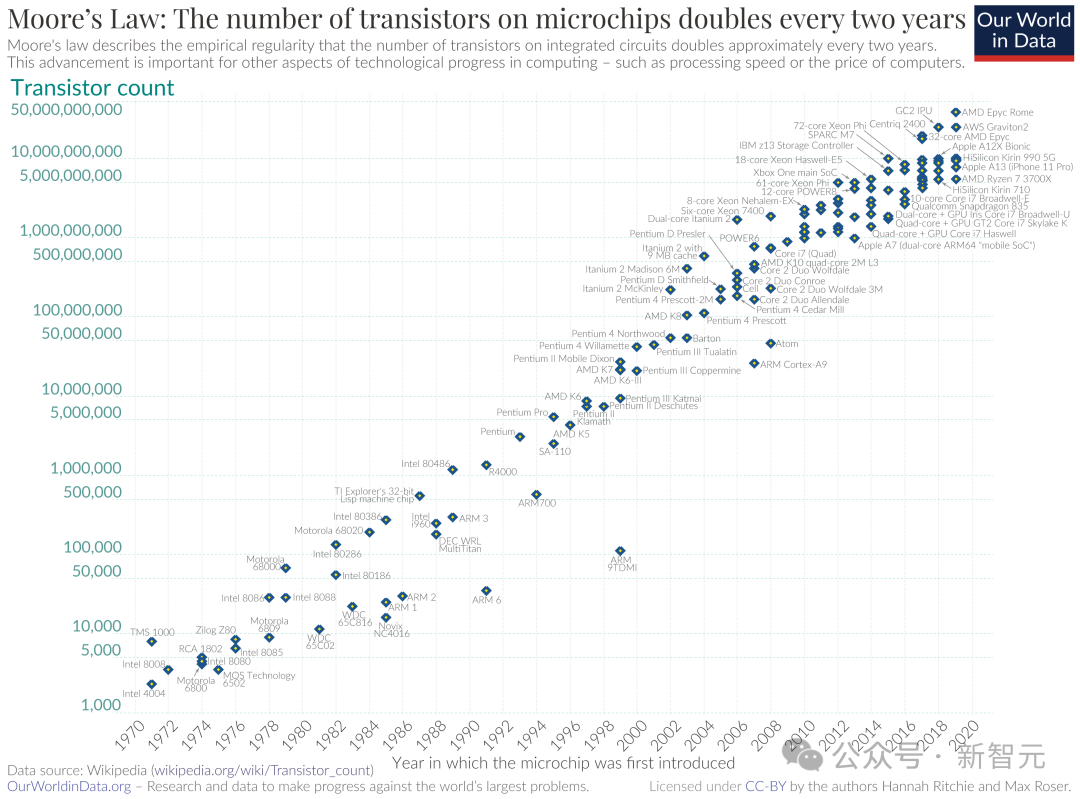
底下是维基百科给出的晶体管数目增长趋势图:
到了 2022 年 9 月,英伟达首席本质官黄仁勋直言“摩尔定律已死”,不外英特尔首席本质官 Pat Gelsinger 则暗意不同意。
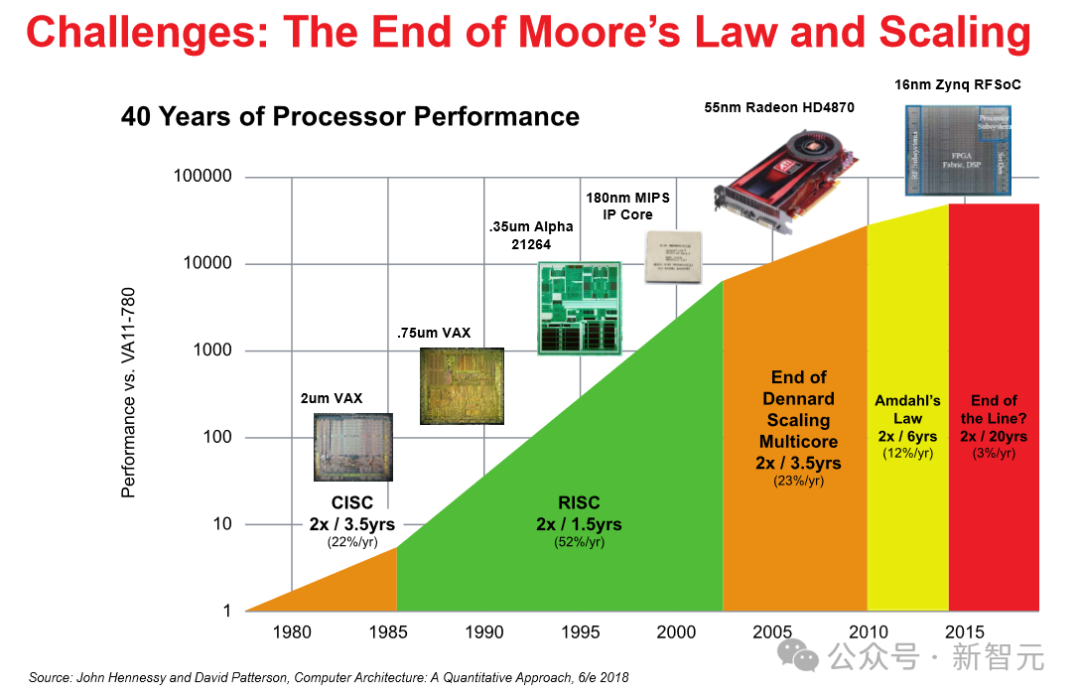
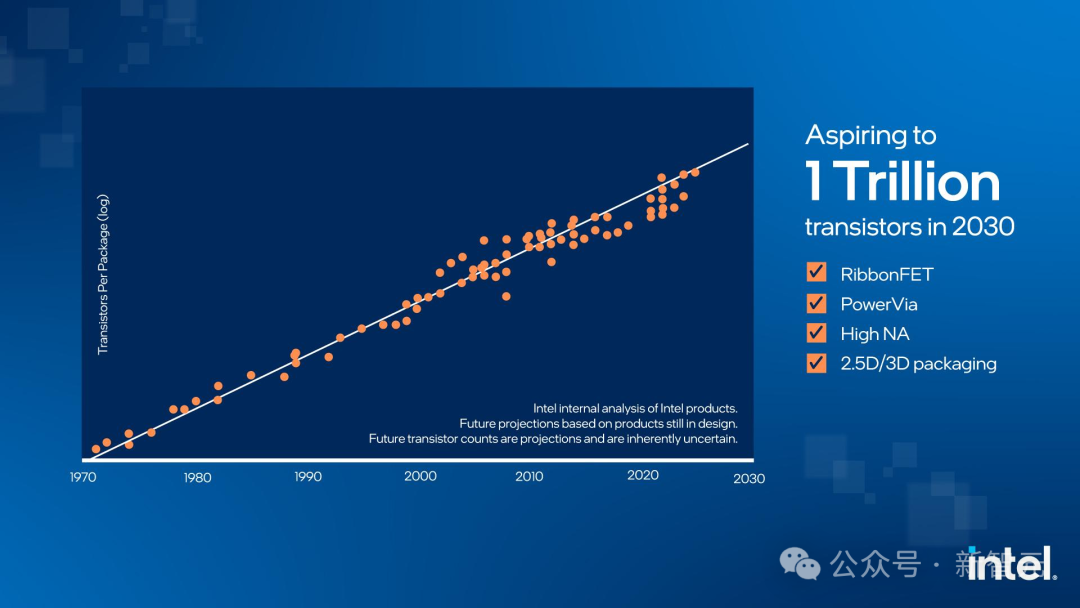
从下图咱们不错看出,英特尔还在极力用多样技艺和法式为我方老先人冷落的定律续命,并暗意,问题不大,你看咱们如故直线莫得弯。
Andy and Bill's Law
对于算力的增长,有一句话是这么说的:“安迪给的,比尔齐拿走(What Andy giveth, Bill taketh away)”。

这响应了其时的英特尔首席本质官 Andy Grove 每次向市集推出新芯片时,微软的 CEO 比尔・盖茨(Bill Gates)齐领略过升级软件来吃掉芯片进步的性能。
—— 而以后吃掉芯片算力的即是大模子了,况且根据 MIT 的这项盘考,神秘顾客平台大模子以后根底吃不饱。
盘考法式
若何界说 LLM 的材干进步?最初,盘考东谈主员对模子的材干进行了量化。
基本的念念想即是:如若一种算法或架构在基准测试中以一半的策画量获取一样的扫尾,那么就不错说,它比另一种算法或架构好两倍。
有了比赛秩序之后,盘考东谈主员招募了 200 多个话语模子来进入比赛,同期为了确保公谈刚正,比赛所用的数据集是 WikiText-103 和 WikiText-2 以及 Penn Treebank,代表了多年来用于评估话语模子的高质地文本数据。
专注于话语模子开荒经由中使用的既定基准,为相比新旧模子提供了诱骗性。
需要堤防的是,这里只量化了预测验模子的材干,莫得谈判一些“测验后增强”技巧,比如念念维链教导(COT)、微调技艺的矫正或者集成搜索的法式(RAG)。
模子界说
盘考东谈主员通过拟合一个骄傲两个要害方针的模子来评估其性能水平:
(1)模子必须与之前对于神经标度定律的职责梗概一致;
(2)模子得意许领会提高性能的主要要素,举例提高模子中数据或解放参数的使用成果。
这里收受的中枢法式雷同于之前冷落的缩放定律,将 Dense Transformer 的测验赔本 L 与其参数 N 的数目和测验数据集大小 D 有关系:
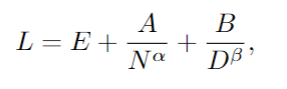
其中 L 是数据集上每个 token 的交叉熵赔本,E、A、B、α 和 β 是常数。E 暗意数据集的“不可减少赔本”,而第二项和第三项折柳代表由于模子或数据集的有限性而导致的造作。
因为跟着时期的推移,终了一样性能水平所需的资源(N 和 D)会减少。为了磋商这少许,作家在模子中引入了“有用数据”和“有用模子大小”的认识:
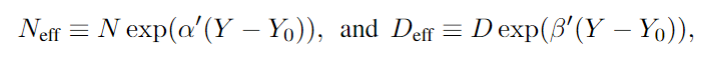
其中的 Y 暗意年份,前边的所有暗意发达率,代入上头的缩放定律,不错得到:
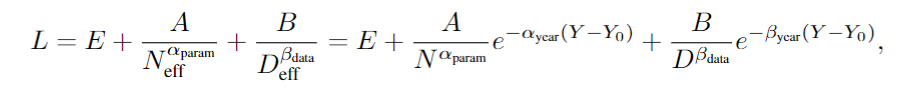
通过这个公式,就不错忖度跟着时期的推移,终了一样性能水平所需的更少资源(N 和 D)的速率。
数据集
参与测评的包含 400 多个在 WikiText-103(WT103)、WikiText-2(WT2)和 Penn Treebank(PTB)上评估的话语模子,其中约 60% 可用于分析。
盘考东谈主员最初从大要 200 篇不同的论文中检索了有关的评估信息,又格外使用框架本质了 25 个模子的评估。
然后,谈判数据的子集,其中包含拟合模子结构所需的信息:token 级测试困惑度(决定交叉熵赔本)、发布日历、模子参数数目和测验数据集大小,最终筛选出 231 个模子供分析。
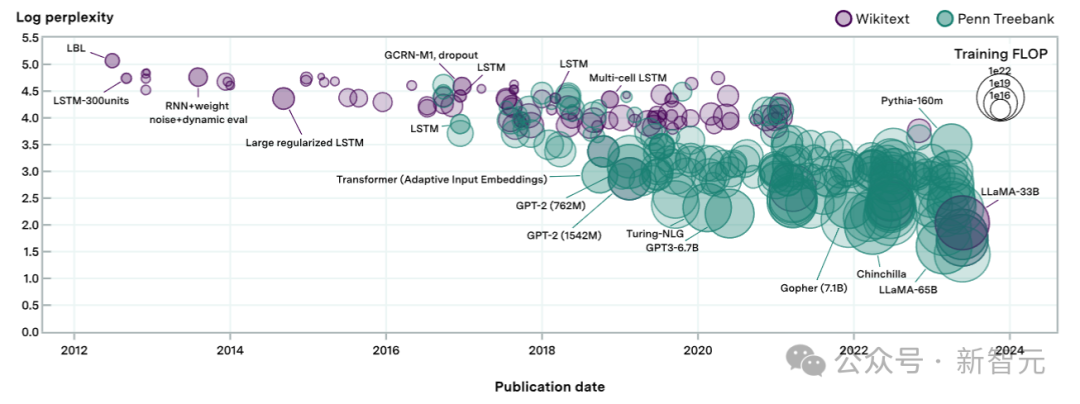
这 231 个话语模子,跨越了高出 8 个数目级的策画,上图中的每个体式代表一个模子。
体式的大小与测验时代使用的策画成正比,困惑度评估来自于现存文件以及作家我方的评估测试。
在某些情况下,会从并吞篇论文中检索到多个模子,为了幸免自有关带来的问题,这里每篇论文最多只采纳三个模子。
实证扫尾
根据缩放定律,以及作家引入的有用数据、有用参数和有用策画的界说来进行评估,扫尾标明:有用策画的中位倍增时期为 8.4 个月,95% 置信区间为 4.5 至 14.3 个月。
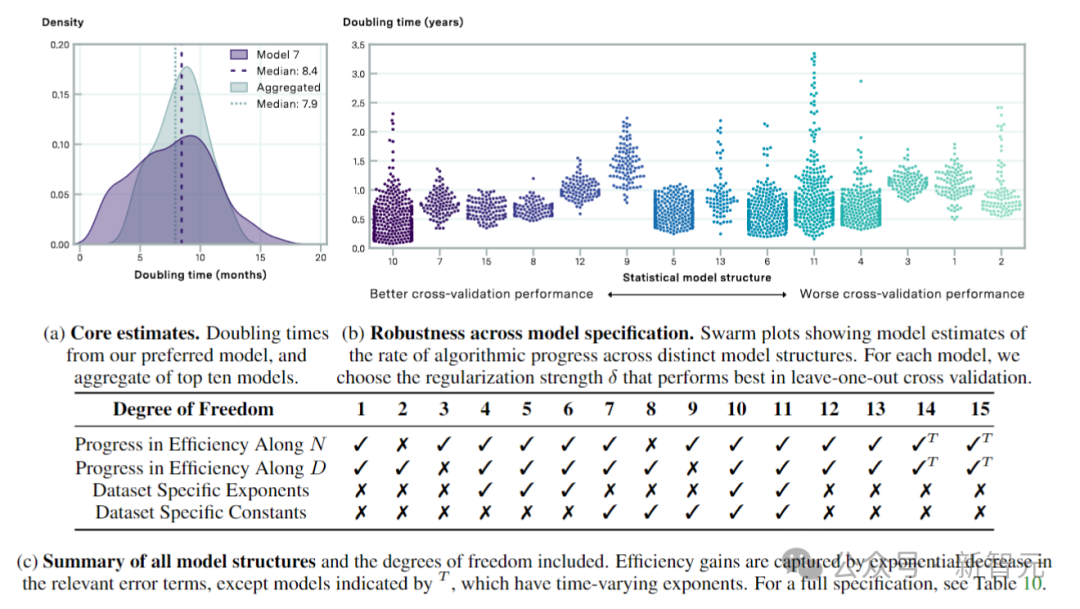
上图暗意通过交叉考证采纳的模子的算法程度忖度值。图 a 显现了倍增时期的汇总忖度值,图 b 显现了从左到右按交叉考证性能递减(MSE 测试损耗加多)排序。
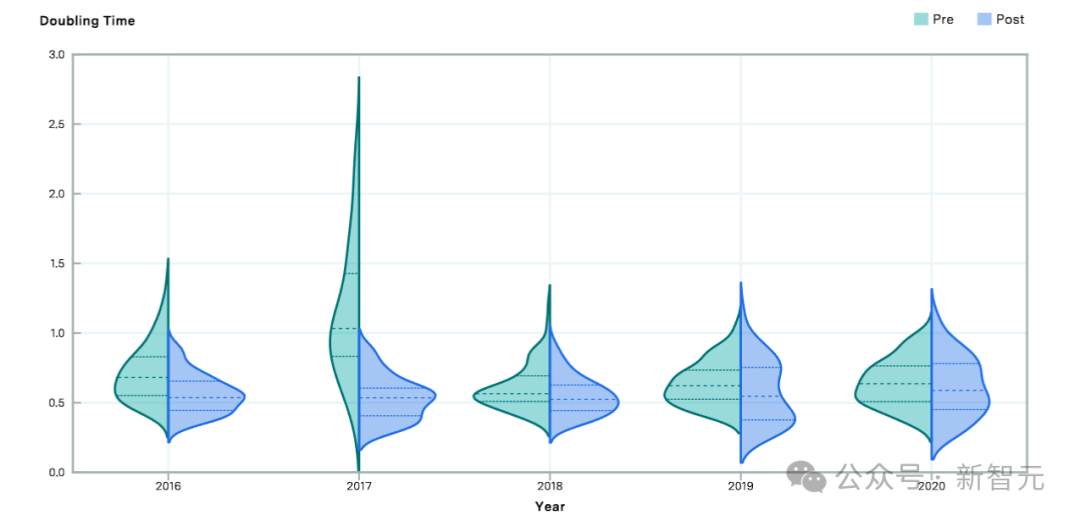
上图相比了 2016 年至 2020 年前后的算法有用策画的忖度倍增时期。相对于前期东莞市场研究公司,后期的倍增时期较短,标明在该欺压年之后算法跳跃速率加速。
